










.jpg "3 TIPs to Reduce Emotional Overwhelm - 19")
.png "3 Strategies for Becoming a Better Parent - 68")

Latest from quick and dirty tips

A Money Girl listener named Eric says, “I really appreciate listening to your show and all the great information you give. I have a question reg...

In today’s world, marketing for law firms is undergoing significant changes due to new technologies, changing client behaviors, and increased co...
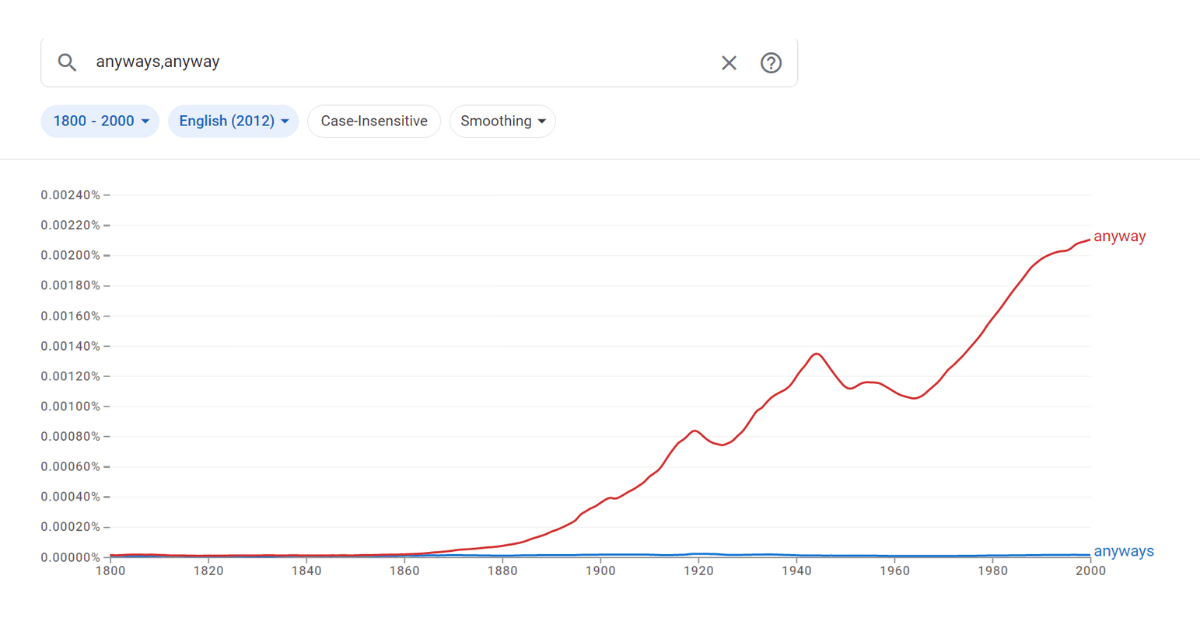
Anabell asked, “Is it correct or incorrect to say ‘anyways’ to someone? As in ‘Anyways, call me later!’ ‘Anyways&r...
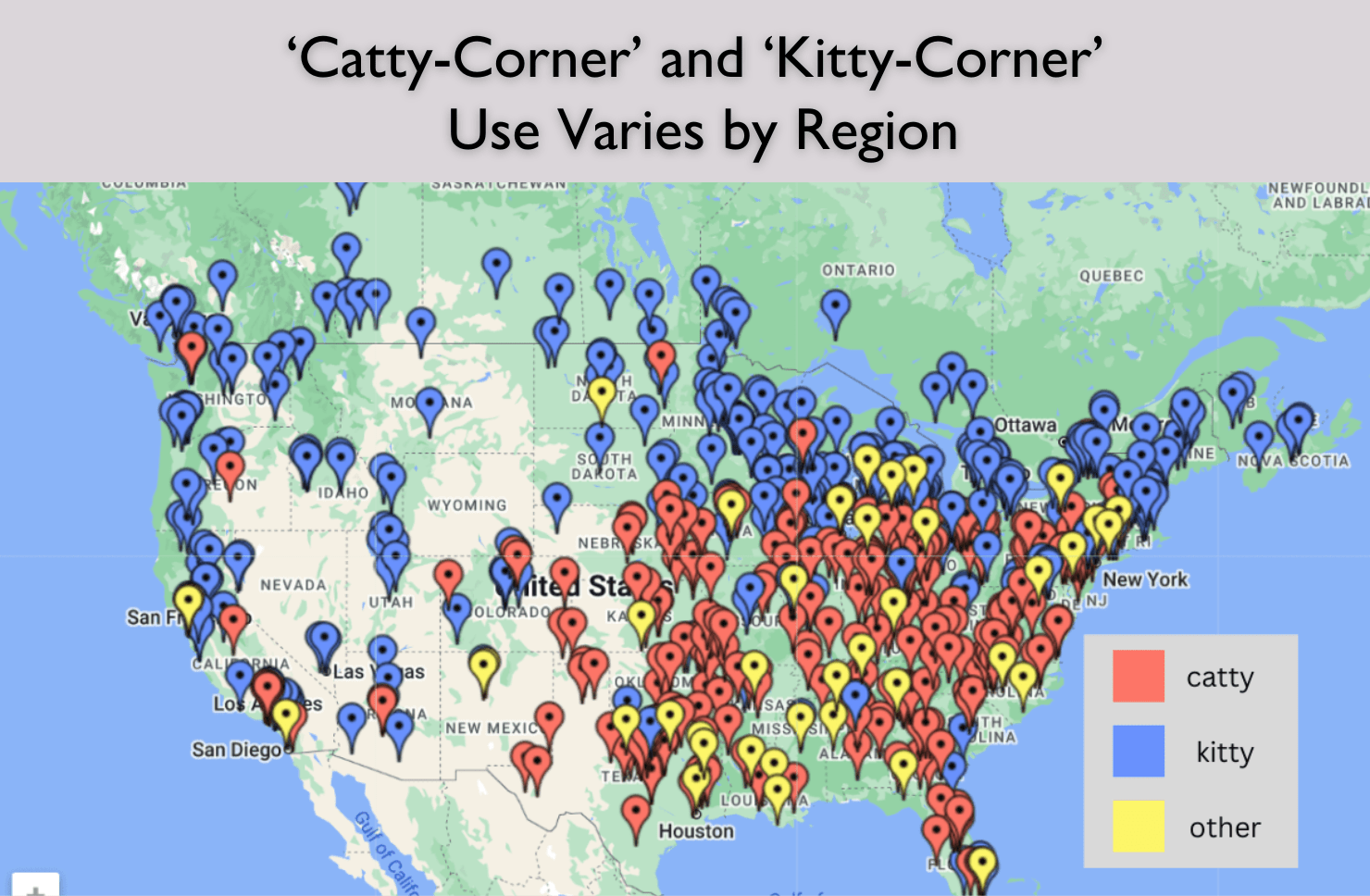
If you watched the recent “Curb your Enthusiasm” finale on HBO, you may have been delighted to see the old Americanism “catawampus&r...

Embarking on a journey to Madrid promises an enchanting experience filled with rich culture, delectable cuisine, and captivating sights. However, to t...
Get texts from Grammar Girl
trending

1

2












